Lors de sa première mise en ligne, l’outil « Faky » de la RTBF s’était pris une volée de bois vert, notamment pour les résultats de son analyse du média Médor, et avait très rapidement été mis hors ligne (voir par exemple ici). La nouvelle version est-elle mieux? Pas sûr…
Si la question fait débat depuis des lustres, certains spécialistes affirment sans ambages que l’appelation « intelligence artificielle » est un abus de langage puisque les algorithmes ne « réfléchissent » pas : ils appliquent. C’est, entre autres, l’avis du co-créateur de Siri, qui en a d’ailleurs fait un livre (L’intelligence artificielle n’existe pas, voir une de ses interviews ici), ou encore Gérard Berry (voir ici). Si les algorithmes apprennent désormais extrêmement vite et offrent des résultats parfois bluffants, ils ont néanmoins toujours besoin qu’on leur fournisse des règles, avec ou sans bases de données (plus ou moins biaisées mais passons, ce n’est pas le sujet ici). Un algorithme qui permet de chercher un mot dans un PDF de 537 pages c’est très facile à faire, très efficace et très utile. Un algorithme qui est capable de reconnaissance faciale, c’est beaucoup plus compliqué, mais ça reste le résultat d’un apprentissage automatique à partir d’énormes bases de données. Mais contrairement à d’autres domaines, l’analyse sémantique et/ou syntaxique ne peut pas être enfermée dans des règles simples et univoques (ce dont un algorithme a besoin) : c’est une des raisons de la beauté de la langue et de la créativité des locuteurs! Et quand bien même ce serait possible, il est très facile de contourner ces règles et de faire passer, par exemple, un discours militant en un discours objectif et neutre. Si l’analyse automatique du langage naturel permet l’existence des assistants vocaux (avec leurs nombreux ratés bien sûr), il est à mon sens illusoire de penser que des algorithmes peuvent sérieusement remplacer l’analyse d’un humain pour évaluer la fiabilité d’un texte ou d’une source. Parce que l’intelligence humaine n’est pas un algorithme, comme l’explique Olivier Houdé dans son essai éponyme. Concernant Faky, manifestement le résultat n’est pas à la hauteur des espérances de ses commanditaires, malgré les promesses marketing de ses exécuteurs…
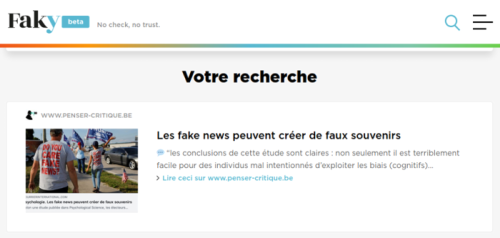
Je viens de faire le test avec un article repris sur ce site. Cet article présente un article original du Courrier international, présentant lui-même les résultats d’une étude parue dans la revue à comité de lecture Psychological Science.
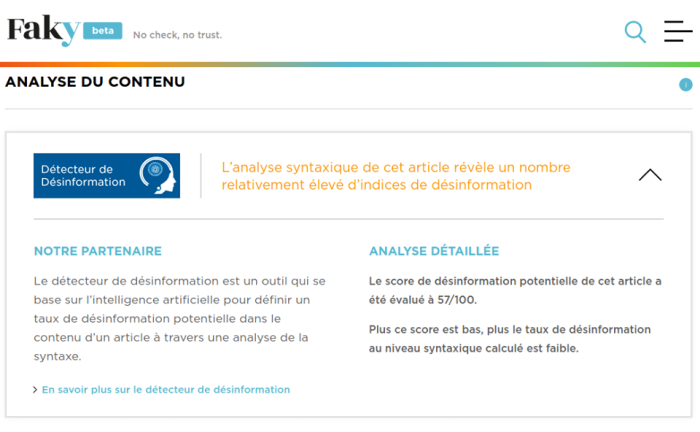
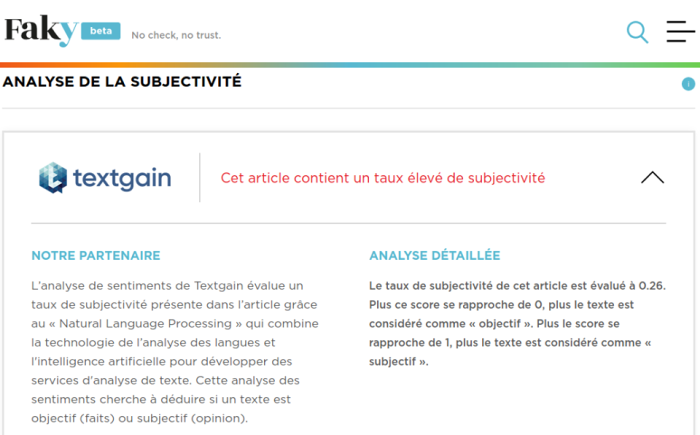
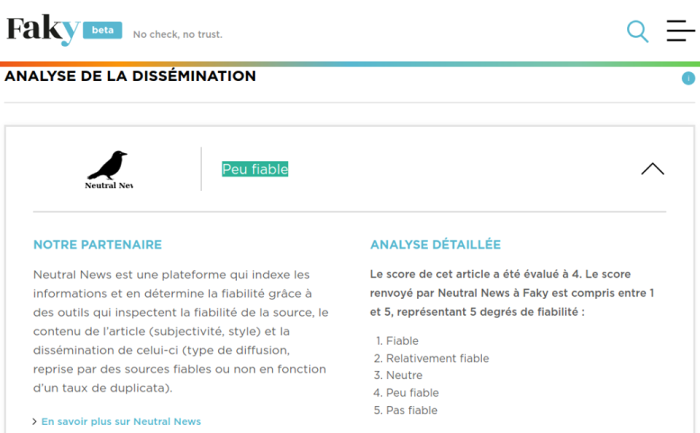
Le résultat du travail automatisé d’évaluation de ces algorithmes :
1. « L’analyse syntaxique de cet article révèle un nombre relativement élevé d’indices de désinformation » ;
2. « Cet article contient un taux élevé de subjectivité » ;
3. « Peu fiable ».
La RTBF a donc dépensé je ne sais pas combien (mais je serais très curieuse de le savoir) dans un ènième outil de fact-checking qui n’apporte rien de plus que tous les autres déjà existant (à part la promesse de l’« objectivité » de la machine…), et ce alors que cette approche est très loin d’être suffisante, comme je l’expliquais ici.
Le lien vers la présentation de l’outil par la RTBF
Lien vers l’outil
Laisser un commentaire